Back to blog list
The Secret to 40% Faster Zendesk Ticket Processing for Attachment-Heavy Workflows: Zero Downloads, Zero Copy-Paste, Self-Processing Documents

Summary: What if your document attachments could read themselves? With self-processing documents, they can. Support agents spend up to 40% of their time manually processing document attachments—downloading PDFs, extracting data, and typing information into ticket fields. This hidden tax costs teams thousands of hours annually while introducing a 15% error rate in manual data entry. Self-processing documents flip this workflow entirely. When an attachment arrives in Zendesk, UpBrains AI automatically identifies the document type, extracts structured data with confidence scores, populates custom fields, posts a layout-preserved readable version as a comment, and routes the ticket to the right team—all before your agent even opens the ticket. The technology behind this is layout-preserving AI OCR, which maintains the visual structure of invoices, purchase orders, and other documents so agents can read them without downloading attachments. Pre-built extractors handle common document types out of the box, while a custom extractor builder lets you process any document using plain-language definitions. The result: 70% reduction in document handling time, 99%+ accuracy, and agents who can focus on actually helping customers instead of copying and pasting from PDFs. Get started with a 14-day free trial or let our team build your solution with a satisfaction guarantee.
Picture this: A customer submits a support ticket with an invoice attached. Your agent opens the ticket, downloads the PDF, squints at the invoice to find the invoice number, manually types it into a custom field, copies the amount, switches back to Zendesk, pastes it in, then writes a response asking for clarification because they couldn't read the vendor name clearly.
Sound familiar?
Now multiply that by hundreds of tickets per day, across your entire support team. According to our research, support agents spend up to 40% of their time on document-related tasks—opening attachments, extracting information, and manually entering data into ticket fields.
But here's what really surprised us: It's not just the time that's the problem. It's the invisible costs—the 15% error rate in manual data entry, the delayed resolutions, and the customer frustration when agents ask for information that was already in the attachment.
What if documents could process themselves the moment they hit your Zendesk inbox?
The Hidden Burden with Document Attachments in Zendesk
Zendesk is brilliant at managing conversations. But when it comes to document attachments—invoices, purchase orders, IDs, bank statements, shipping documents—it treats them as opaque files. Black boxes that agents must manually open, read, and interpret.
This creates a cascade of inefficiencies:
The Manual Processing Tax
Every document attachment triggers the same painful workflow: download, open, read, extract, type, switch applications, paste, verify. For a single invoice, this takes 3-5 minutes. For complex documents like bills of lading or multi-page statements, it can take much longer.
The Error Epidemic
When humans manually transcribe data from documents into ticket fields, errors are inevitable. Invoice numbers get transposed. Dates get misread. Amounts lose decimal places. These errors don't just slow down resolution—they can trigger compliance issues, billing disputes, and customer churn.
The Searchability Black Hole
Here's a scenario every support manager dreads: "Find me all tickets from last quarter where the invoice amount exceeded $10,000." If that data lives only in PDF attachments, you're facing hours of manual review. Document content trapped in attachments is invisible to Zendesk's search and reporting.
The Context Switching Penalty
Agents constantly bounce between Zendesk, PDF viewers, and other applications. Each context switch breaks focus and adds cognitive load. Studies show it takes an average of 23 minutes to fully regain focus after a distraction. Your agents are being distracted dozens of times per day.
Enter Layout-Preserving AI OCR: A Different Approach
Traditional OCR (Optical Character Recognition) has been around for decades. It can extract text from documents. But here's the problem: it strips away all the visual structure that makes documents readable.
An invoice isn't just text—it's a carefully designed layout with headers, tables, columns, and visual hierarchy. When traditional OCR flattens this into a wall of text, you lose the very structure that makes the information comprehensible.
Layout-preserving OCR is different.
When UpBrains AI processes a document, it doesn't just extract text—it understands and maintains the document's visual structure. Tables remain tables. Columns stay aligned. The invoice that took your designer hours to format still looks like an invoice when it appears in your Zendesk ticket.
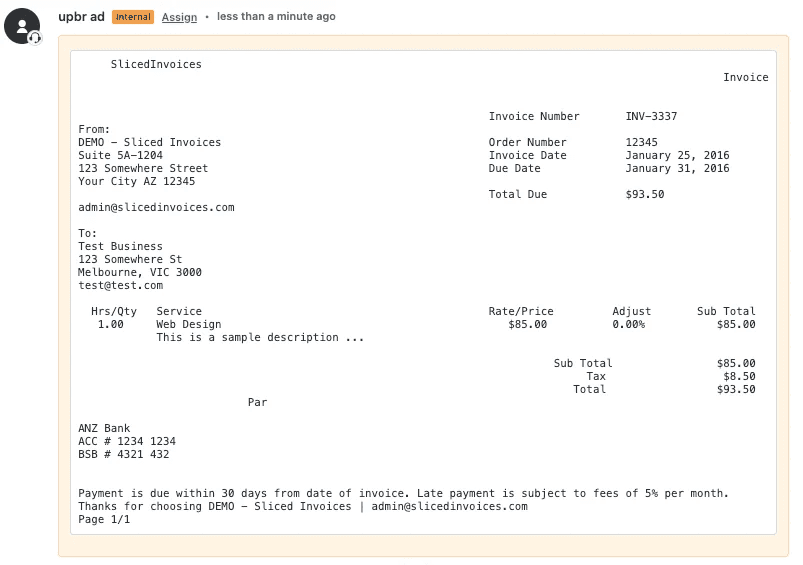
This might sound like a small thing. It's not.
When we post extracted document content as a Zendesk comment with preserved layout, agents can read it exactly as if they'd opened the original attachment. No downloading. No switching applications. No squinting at PDFs. The document content is right there in the ticket, formatted and readable.
But layout preservation is just the beginning.
Beyond OCR: Intelligent Document Extraction
Reading documents is one thing. Understanding them is another.
UpBrains AI doesn't just convert images to text—it extracts structured, actionable data. When we process an invoice, we don't just give you the text "INV-3337" somewhere in a blob of content. We give you:
Invoice Number: INV-3337 (98% confidence)
Invoice Date: January 25, 2016 (99% confidence)
Due Date: January 31, 2016 (95% confidence)
Vendor: DEMO - Sliced Invoices (97% confidence)
Total Due: $93.50 (99% confidence)
Line Items: [structured table with descriptions, quantities, prices]
Each field comes with a confidence score. You know exactly how reliable each piece of extracted data is.
And here's where it gets powerful: this structured data can automatically populate Zendesk custom fields, trigger workflows, add tags, and route tickets—all without agent intervention.
Specialized Extractors for Every Document Type
Different documents require different extraction logic. An invoice has different fields than a passport. A bill of lading needs different parsing than a bank statement.
That's why UpBrains AI includes a library of pre-trained, specialized extractors:
Financial Documents
Invoice Extractor (invoice number, dates, vendor, line items, totals, tax, payment terms)
Purchase Order Extractor (PO number, buyer/supplier info, line items, quantities, ship dates)
Bank Statement Extractor (account info, transactions, balances, multi-account support)
Bank Check Extractor (check number, amount, payee, routing/account numbers)
Receipt Extractor (merchant, items, totals, payment method, timestamps)
Logistics & Shipping
Bill of Lading Extractor (shipper, consignee, cargo details, ports, container info)
Airway Bill Extractor (AWB number, origin/destination, weight, dimensions, airline)
Packing Slip Extractor (order numbers, items, quantities, weights, shipment details)
CMR Consignment Note Extractor (international road transport documentation)
Identity Documents
Passport Extractor (name, nationality, passport number, DOB, expiry, MRZ data)
Driver License Extractor (name, DOB, address, license number—US, UK, EU, CA, AU)
Government ID Extractor (national ID cards from major countries)
Each extractor has been trained on thousands of real-world documents and achieves 99%+ accuracy on well-formatted documents.
Custom Extractors: Because Your Documents Are Unique
What if your business uses document types that aren't in our pre-built library? Insurance claim forms. Medical records. Custom contracts. Industry-specific certificates.
This is where the AI-powered Custom Extractor Builder comes in.
You don't need machine learning expertise. You don't need to label training data. You simply describe what you want to extract in plain English:
"Extract the policy number, claim amount, incident date, claimant name, and damage description from insurance claim forms."
UpBrains AI generates an extractor based on your description. You test it on sample documents, refine the field definitions if needed, and deploy it to production.
But we didn't stop there.
Custom Validation Logic
Beyond extraction, you can define business rules that validate the extracted data—also in plain language:
"Ensure the invoice total equals the sum of all line items plus tax"
"Verify the expiry date is in the future"
"Check that the PO number matches format ABC-XXXXX"
These validation rules run automatically on every extraction. When validation fails, the document is flagged for review. When it passes, you have confidence the data is not just extracted, but correct.
Deep Zendesk Integration: Triggers, Actions, and Automation
Extraction is powerful. But extraction integrated with your support workflow is transformational.
UpBrains AI connects deeply with Zendesk through a comprehensive set of triggers and actions:
Triggers (What Starts the Automation)
New Ticket Creation
Ticket Status Change
New Public Comment
New Private Comment
Actions (What the Automation Can Do)
OCR All Attachments (extract text from every attached file)
Post as Comment (with layout preservation!)
Update Ticket Fields (populate custom fields with extracted data)
Add Tags (based on document content)
Assign to Agent (route based on document type or content)
Move to Group (escalate based on extracted values)
Create New Ticket (split complex submissions)
Custom API Call (extend with any Zendesk API endpoint)
Let's see what this looks like in practice.
Real-World Workflow: Invoice Dispute Resolution
Before UpBrains AI:
Customer submits ticket with invoice PDF attached
Agent opens ticket, sees attachment
Agent downloads PDF, opens in viewer
Agent manually reads invoice number, amount, date
Agent switches back to Zendesk
Agent types invoice number into custom field
Agent types amount into another custom field
Agent copies key details into their response
Agent submits response
Time elapsed: 5-7 minutes
After UpBrains AI:
Customer submits ticket with invoice PDF attached
UpBrains AI automatically:
Extracts all invoice data
Populates Invoice Number, Amount, Vendor, Due Date custom fields
Posts layout-preserved invoice content as internal comment
Adds tags: "invoice", "billing-dispute", "$50-100"
Routes to Billing Support group
Agent opens ticket, sees all data pre-populated
Agent reads invoice content directly in ticket (no download needed)
Agent resolves issue
Time elapsed: 1-2 minutes
That's a 70% reduction in handling time for a single ticket. Across thousands of tickets per month, the impact is enormous.
The Human-in-the-Loop: Confidence Scores and Document Review
AI isn't perfect. We know that. That's why UpBrains AI is built with human oversight at its core.
Field-Level Confidence Scores
Every extracted field includes a confidence score. Not just an overall document score—a score for each individual field. This precision matters.
An invoice might have the invoice number extracted at 99% confidence, but the due date at only 72% confidence (perhaps it was handwritten or partially obscured). You don't need to review the entire document—just the fields where the AI is uncertain.
Automatic Review Routing
When confidence falls below your configured threshold, UpBrains AI automatically flags the document for human review. It appears in your Document Review Studio—a centralized dashboard where your team can:
See the original document side-by-side with extracted data
Correct any misread fields with a single click
Approve or reject the extraction
Add notes for audit purposes
Continuous Learning
Here's the magic: human corrections feed back into the system. The more your team reviews, the smarter UpBrains AI becomes. Error patterns are identified and addressed. Accuracy improves over time.
Our customers typically see review rates drop from 15-20% initially to under 5% within a few months of active use.
Security and Compliance: Enterprise-Ready
Document processing involves sensitive data. We take that seriously.
Your data stays yours: We never train our models on your documents
No Data Retention Option: You can configure your AI Agents to retain NO DATA in UpBrains AI's storage after processing, another layer of preserving your data privacy and confidentiality.
GDPR compliant & US DPF Certified: Meet the strictest regulatory requirements
Enterprise-grade encryption: Bank-level security for documents in transit and at rest
Complete audit trails: Track every extraction, review, and action
Role-based access control: Define who can see what
Getting Started: Three Paths to Value
We've made it easy to experience UpBrains AI for Zendesk, regardless of where you are in your evaluation process.
Option 1: Free Quick Demo PoC
Want us to show you what's possible with your actual documents? Send us a few sample files from your Zendesk tickets. We'll configure an extractor, run your documents through it, and show you:
Extraction results with confidence scores
Layout-preserved output as it would appear in Zendesk comments
Accuracy report and recommendations
No Zendesk access required. No commitment. Timeline: 3-5 business days.
Option 2: Self-Serve Free Trial (14 Days)
Prefer to explore on your own? Our self-serve portal lets you get hands-on immediately:
Create your free account in minutes
Connect your Zendesk instance with a few clicks
Choose from pre-built automation templates to get started fast
Test document extraction on your real attachments
Experience the full Zendesk integration—triggers, actions, layout-preserved comments
No credit card required. Full access for 14 days. If you love it, upgrade to a paid plan. If not, no strings attached.
Option 3: Done-For-You Onboarding
Want experts to build your solution? Our team (or one of our certified Zendesk partners) will implement everything for you:
Deep discovery session to understand your document workflows
Custom extractors built and tested for your specific document types
Full Zendesk integration configured—triggers, field mapping, routing rules, tagging logic
Layout-preserved commenting deployed and optimized
Team training and documentation
Dedicated success manager and ongoing support
Our Satisfaction Guarantee: If you're not completely satisfied with the implementation, we'll work with you until it's right—or refund your onboarding fee. We're that confident in what we deliver.
Zendesk Partner Packages: Work with one of our certified Zendesk implementation partners to get exclusive onboarding packages and preferred pricing. Our partners bring deep Zendesk expertise combined with UpBrains AI's document processing capabilities—the best of both worlds.
Talk to Our Team | Find a Partner
The Bottom Line
Your support agents shouldn't be data entry clerks. They should be problem solvers, relationship builders, and customer advocates.
Every minute spent manually extracting data from PDF attachments is a minute not spent actually helping customers. Every error from manual transcription is a potential compliance issue or customer frustration.
Layout-preserving AI OCR isn't just a technology upgrade—it's a fundamental reimagining of how document-heavy support workflows should operate.
Documents should process themselves. Data should flow automatically into the right fields. Agents should see document content without leaving Zendesk. And humans should only intervene when AI genuinely needs their judgment.
That's the future we're building. And it's available for Zendesk today.
Ready to see what layout-preserving AI OCR can do for your Zendesk workflow?
Book a Demo | Explore Our Zendesk Integration | Explore Our Extractors
UpBrains AI provides document-centric AI agents for supply chain, distribution, and enterprise operations. Our platform processes millions of documents monthly with 99%+ accuracy, helping teams automate their most tedious document workflows.
Explore other articles
See all blogs

